随手记录学到的知识点
谚语
一脚踩在狗屎上,一滑滑成大会员:形容走了狗屎运
生信
- 正常机体就会通过选择性剪接产生各种提前出现的密码子转录本来调节基因的表达量。因此密码子通读这种疗法有一个缺陷,它不是靶向的,所有提前出现的终止密码子都有概率被通读,会干扰正常的基因表达调控。
ssl证书
hexo配置ssl证书需要安装npm install express --save
nginx
网站打开问题可以查看nginx的报错日志:cat /var/log/nginx/error.log
snakemake
BUG
- 使用lambda函数从字典中获取rule的input时,随机出现Keyerror错误。猜想1:snakemake检测input使用了多线程,导致偶发性的多线程冲突。
1
2
3
4
5
6
7
8
9
10
11sampleInfo = {
"ID01": {"3":"ID01.R1.fa", "5":"ID01.R2.fa"},
"ID02": {"3":"ID02.R1.fa", "5":"ID02.R2.fa"},
...
"ID20": {"3":"ID20.R1.fa", "5":"ID20.R2.fa"},
}
rule test:
input:
ab1_file_L3 = lambda wildcards: sampleInfo[wildcards.sid]["3"],
ab1_file_L5 = lambda wildcards: sampleInfo[wildcards.sid]["5"]
尝试修改:运行一段时间看看还会不会有出现这个错误(2024.9.2)。1
2
3
4
5
6
7
8def ab1_dict_from_sample(wildcards):
return {
"ab1_file_L3": sampleInfo[wildcards.sid]["3"],
"ab1_file_L5": sampleInfo[wildcards.sid]["5"]
}
rule test:
input:
unpack(ab1_dict_from_sample)
↑ 没效果(2024.9.6)
重新设计了解决方法,尝试使用try重复获取发生了错误的Key(2024.9.9):↑ 没效果(2024.9.12)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import time
def ab1_dict_from_sample(wildcards, count = 0):
if count == 10:
return {
"ab1_file_L3": sampleInfo[wildcards.sid]["3"],
"ab1_file_L5": sampleInfo[wildcards.sid]["5"]
}
try:
getData = {
"ab1_file_L3": sampleInfo[wildcards.sid]["3"],
"ab1_file_L5": sampleInfo[wildcards.sid]["5"]
}
except KeyError:
print ("show sampleID:", sampleInfo.keys())
time.sleep(3)
count += 1
getData = ab1_dict_from_sample(wildcards, count)
return getData
rule test:
input:
unpack(ab1_dict_from_sample)
但是明确了一点:发生错误的键值对的确从sampleInfo中被删除了,因此决定将sampleInfo转为静态变量(2023.9.13)1
2import types
sampleInfo = types.MappingProxyType(sampleInfo)
Git
commit message 规范
commit message包含三部分:Header,Body和Footer
1 | <type>(<scope>): <subject> |
Header是必需的,Body和Footer则可以省略
Header
- type(必需)
用于说明git commit的类别,允许使用下面几个标识。feat:新功能fix/to:bug修复。to指部分修复,fix指完全修复。docs:修改附属文档。style:调整了代码书写格式,不影响代码运行。refactor:代码重构。perf:性能优化test:增加测试chore:构建过程或辅助工具的变动revert:回滚merge:代码合并sync:同步主线或分支的 Bug,通常用于解决因为合并而引入的问题。
Git commit工具
Commitizen
用于撰写合格的Git提交信息。
首先,全局安装Commitizen:1
2
3su -
npm install -g commitizen
exit然后,在项目目录中运行下方命令,使文件夹支持Angular规范的Commit message。
1
commitizen init cz-conventional-changelog --save --save-exact
需要提交修改时,使用
git cz替换git commit,可以打开Commitizen的引导界面。在这个交互式界面中,你可以选择提交的类型(feat、fix、docs 等)、影响的范围(scope)、简短的描述(subject)以及其他相关信息。vscode插件(git-commit-plugin)
支持emoji表情
图像去重、人物识别、系列图片分组
图片去重
可以使用imagededup。
人物识别
不只是最简单的面部识别,还需要解决面部缺失时的识别问题。
研究方向
- 将皮肤特征经过标准化转换后投影成一个image。每个像素对应了一块皮肤特征,分辨率由这块皮肤大小决定。每个像素包含了皮肤的斑纹特征。同时,由于经过了标准化转换,因此每个像素中还包含了比例信息。直观地说,就是根据图片集构建了对象皮肤特征的三维模型,将三维模型不等比缩放成标准人体模型大小,最后转为二维化保存。
由照片生成三位模型的时候必需考虑到阴影、妆容、服装对皮肤斑纹特征和人体形状的影响。
系列图片分组
根据人物识别、背景、服装等条件,对图片进行归类分组。
MobileNet
MobileNet(出自论文MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications)是轻量化模型中的经典网络。传统卷积神经网络的内容需求大、运算量大、无法在移动设备和嵌入式设备上运行。在此基础上,Google针对手机等嵌入式设备提出了MobileNet,一种轻量化深度神经网络,其核心思想是深度可分离卷积(Depthwise Separable Convolution)。目前,MobileNet在移动端图像分类、目标检测、语义分割等任务上均取得了优秀的表现。
MobileNetV1论文: 阅读笔记
MobileNetV3论文
MobileNetV3采用了很多新的技术,包括针对通道注意力的Squeeze-and-Excitation模块、NAS搜索方法等,这些方法都有利于进一步提升网络的性能。
MobileNet发展史
MobileNet V1
MobileNet V1是由Google在2016年提出的,其主要创新点在于深度卷积(Depthwise Convolution),而整个网络实际上也是深度可分离模块的堆叠。
深度可分离卷积是MobileNet的基本单元,其实这种结构之前已经在Inception模型中使用了。深度可分离卷积其实是一种可分解卷积操作,该操作也可以分解为两个更小的卷积操作:深度卷积和逐点卷积(Pointwise Convolution),如图所示。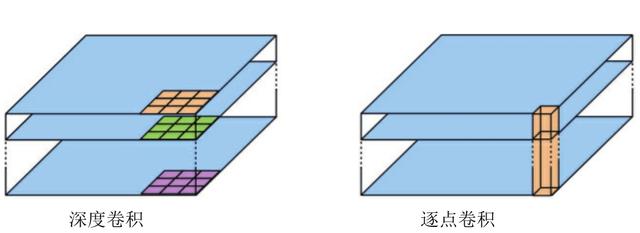
深度卷积与标准卷积不同。对于标准卷积,其卷积核用在所有输入通道(Input Channel)上,而深度卷积针对每个输入通道采用不同的卷积核,即一个卷积核对应一个输入通道。所以说深度卷积是逐通道的操作,而逐点卷积其实就是普通的1×1卷积。
对于深度可分离卷积,首先采用深度卷积对不同的输入通道分别进行卷积,然后采用逐点卷积将上面的输出进行结合。这样做的整体效果与一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。
MobileNet V1,存在以下两个问题:
a) MobileNet V1的结构过于简单,没有复用图像特征,即没有Concat或Add等操作进行特征融合,而后续一系列的ResNet、DenseNet等结构已经证明复用图像特征的有效性。
b) 深度可分离卷积问题。在处理低维数据时,ReLU激活函数会造成信息的丢失。深度可分离卷积由于本身的计算特性决定了它本身没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。因此,如果上一层给它的通道很少,那么它也只能使用在低维空间提取到的一些Low-Level特征,这可能会带来性能问题。
为了解决上述问题,MobileNet V2应运而生。MobileNet V2
对于深度可分离卷积中的第2个激活函数,在MobileNet V2中修改为“线性激活”,论文中称其为“Linear Bottleneck”。论文作者认为ReLU激活函数在高维空间能够有效提升MobileNet V2的非线性;而在低维空间则会破坏特征、损失特征的信息,性能可能并不如线性激活函数好。
如图,对于结构设计问题,MobileNet V2在MobileNet V1的Block==>卷积模块中的深度可分离卷积前增加了一个逐点卷积(1×1卷积+BN+ReLU6),专门用来提升特征的维度,这样便可以得到High-Level特征,从而提升模型的性能。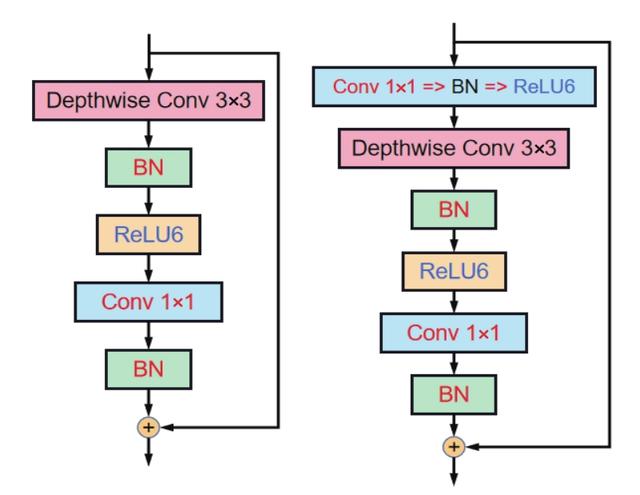
MobileNet V2同样借鉴了ResNet,采用了残差结构,将输出与输入相加,但是ResNet中的残差结构是先降维卷积再升维,而MobileNet V2则是先升维卷积再降维。
ResNet的残差结构更像一个沙漏,而MobileNet V2中的残差结构则更像是一个纺锤,两者刚好相反。因此论文作者将MobileNet V2的结构称为“Inverted Residual Block”。为了解决深度卷积的局限问题,特征提取能够在高维进行。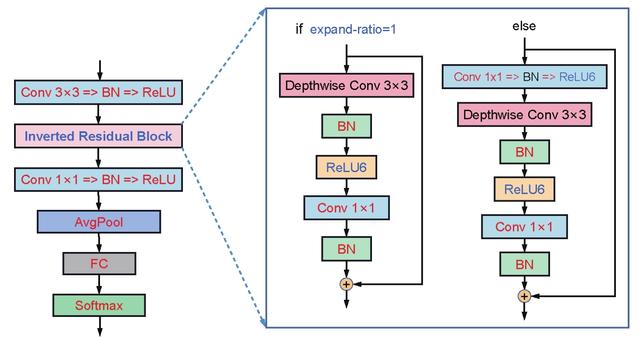
上图为MobileNet V2的整体架构。MobileNet V3
MobileNetV3的整体架构基本沿用了MobileNetV2的设计,采用了轻量级的深度可分离卷积和残差块等结构,依然是由多个模块组成,但是每个模块得到了优化和升级,包括瓶颈结构、SE模块和NL模块。MobileNetV3在ImageNet 分类任务中正确率上升了 3.2%,计算延时还降低了20%。
整体来说MobileNetV3有两大创新点:
a) 互补搜索技术组合:由资源受限的NAS执行模块级搜索,NetAdapt执行局部搜索。
b) 网络结构改进:将最后一步的平均池化层前移并移除最后一个卷积层,引入h-swish激活函数。
MobileNetV3 有两个版本,MobileNetV3-Small 与 MobileNetV3-Large 分别对应对计算和存储要求低和高的版本。
这是论文中给出的网络结构,值得注意的是第一个卷积核的个数为16,并且采用了HS激活函数;表中exp_size代表benck中第一部分升维后的channel,SE代表是否使用SE模块,NL表示激活函数的类型,HS代表hard-swish激活函数,RE代表ReLU激活函数,s代表步长。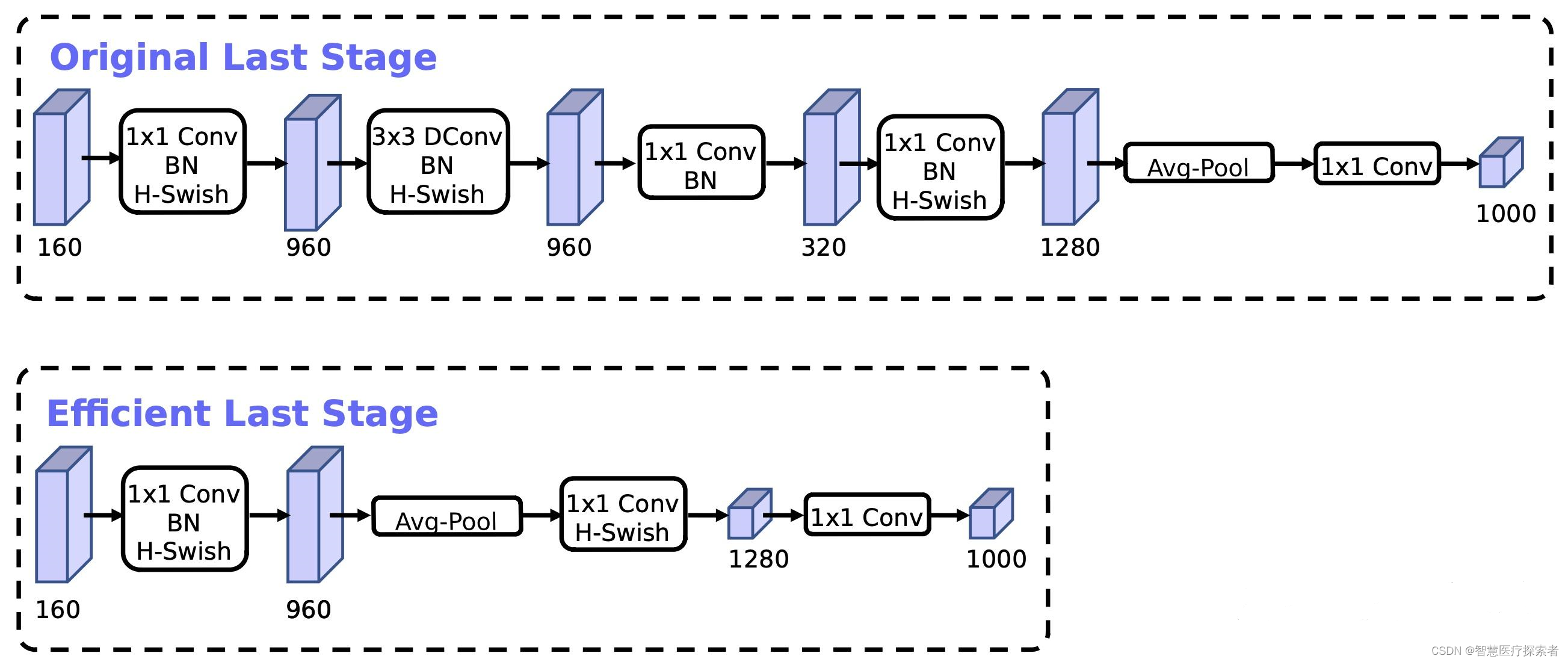
1)MobileNetV3-Large的网络结构: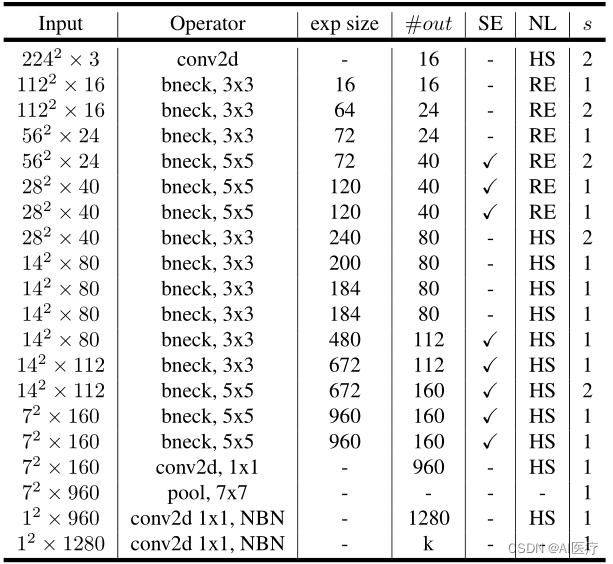
2)MobileNetV3-Small的网络结构: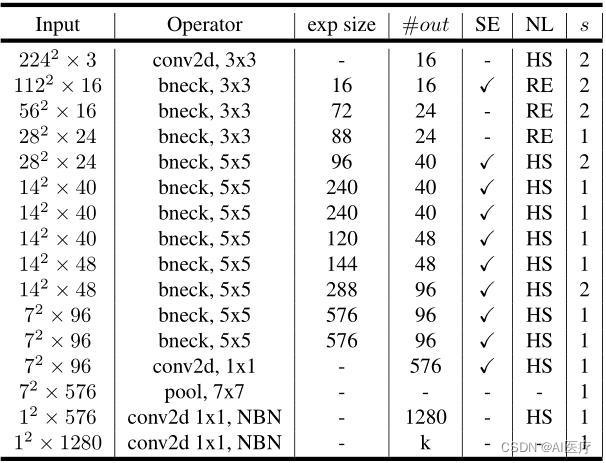
3)MobileNetV3特有的bneck结构: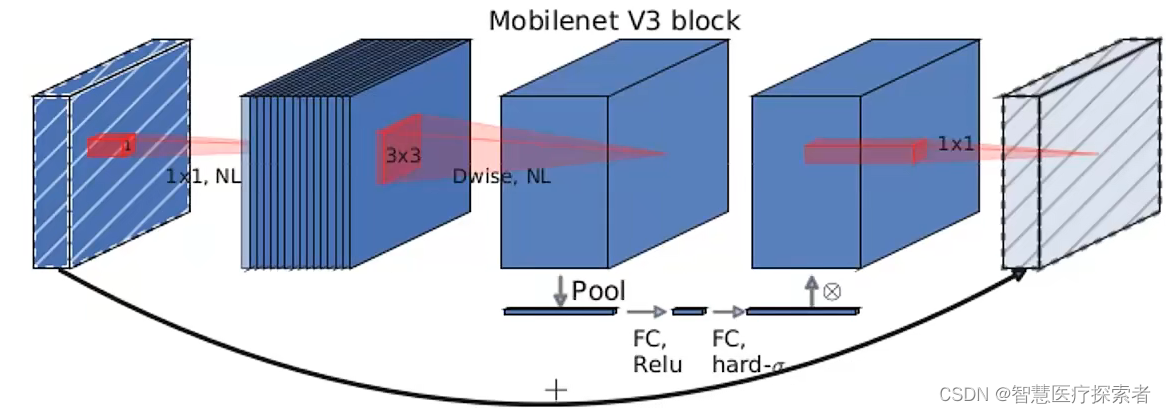
MobileNet模型比较
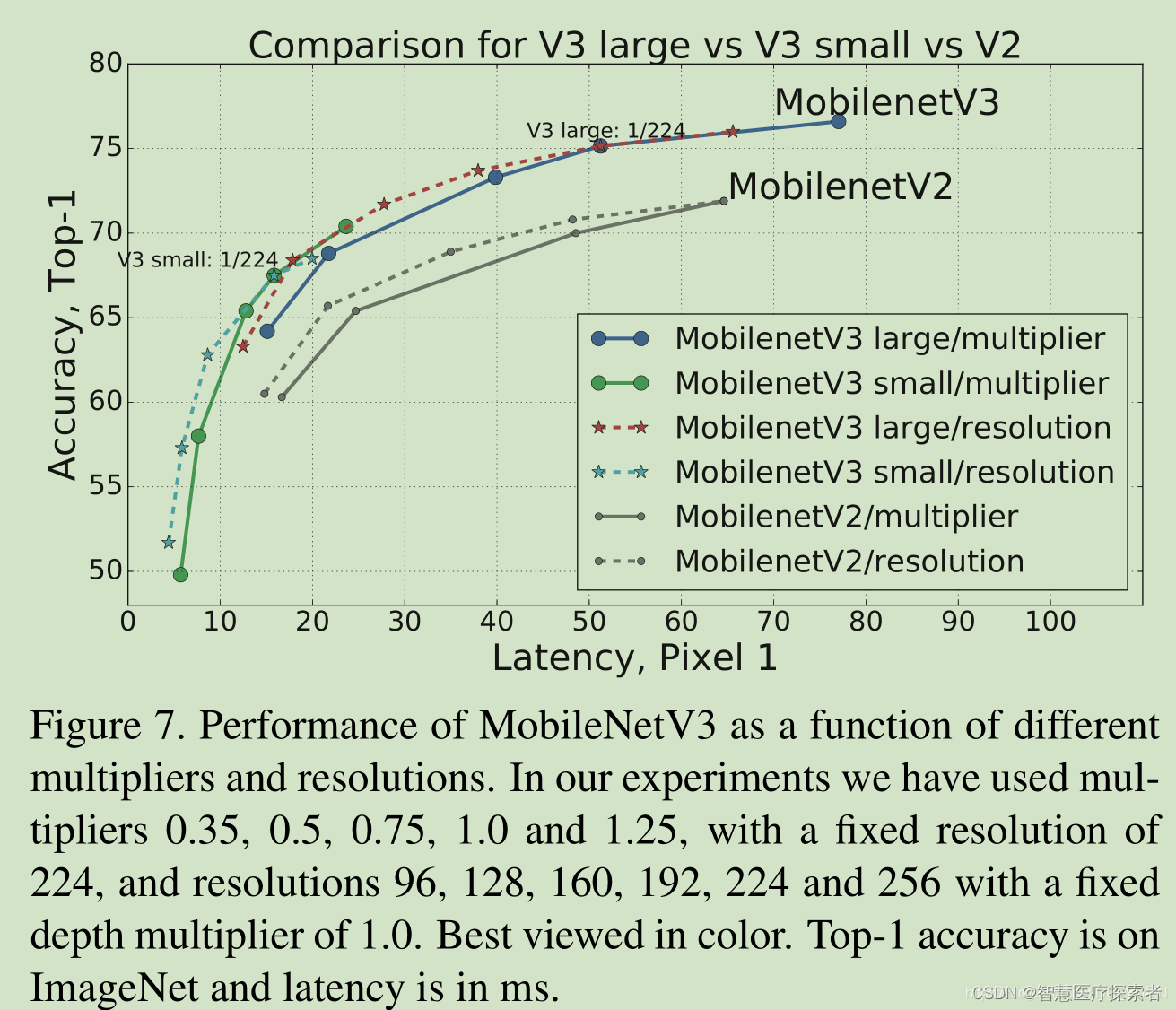
MobileNetV3在CIFAR10数据集上的实现
cifar-10数据集
Cifar-10是由Hinton的学生Alex Krizhevsky、Ilya Sutskever收集的一个用于普适物体识别的计算机视觉数据集,它包含60000张32X32的RGB彩色图片,总共10个分类。其中,包括50000张用于训练集,10000张用于测试集。

CIFAR-10数据集中一共包含10个类别的RGB彩色图片:飞机(airplane)、汽车(automobile)、鸟类(bird)、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck)。
CIFAR-10是一个更接近普适物体的彩色图像数据集。与MNIST数据集相比,CIFAR-10具有以下不同点:
a) CIFAR-10 是3通道的彩色RGB图像,而MNIST是灰度图像。
b) CIFAR-10 的图片尺寸为32×32,而MNIST的图片尺寸为28×28,比MNIST稍大。
相比于手写字符,CIFAR-10含有的是现实世界中真实的物体,不仅噪声很大,而且物体的比例、特征都不尽相同,这为识别带来很大困难。直接的线性模型如Softmax在CIFAR-10上表现得很差。
基于pytorch的代码实现
1 | from torch.utils.data import DataLoader |
运行结果
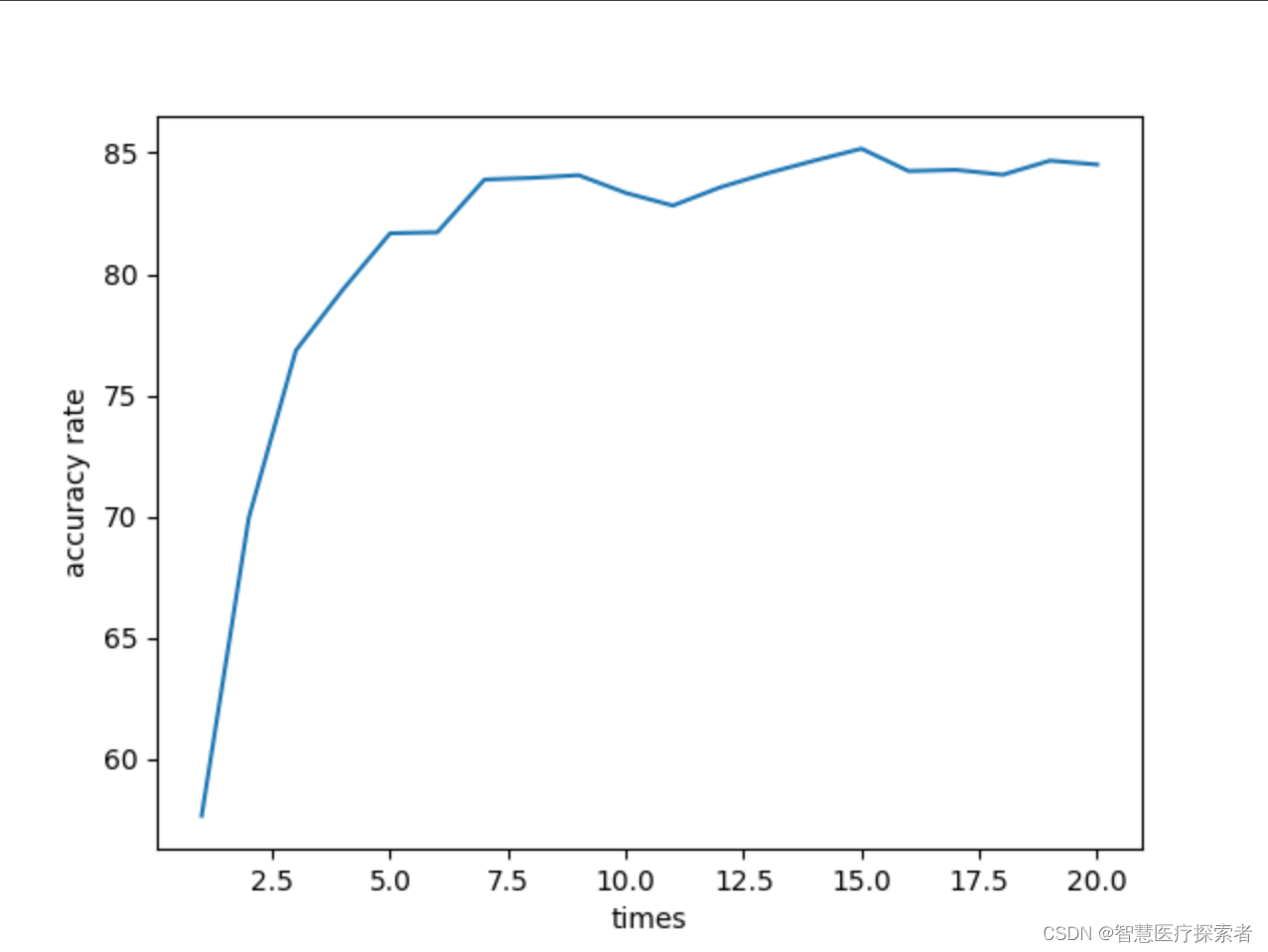
1 | 2023-12-22 16:21:26, train epoch: 0/20 |
疑问
- 爱因斯坦环在什么条件下会变成爱因斯坦十字?